-flowing-like-streams-into-a-glowing,-three-dimensional-database-structure.-the-database-is-represen.webp)

Amazon DynamoDB is a fully managed NoSQL database service that provides high availability, scalability, and low-latency performance, making it an excellent choice for storing and querying large volumes of processed Kafka log data. In log processing pipelines, DynamoDB serves as a durable, scalable store for logs that are processed by Lambda and analyzed by machine learning models, such as SageMaker's Random Cut Forest (RCF). DynamoDB’s ability to handle large amounts of real-time data with minimal operational overhead allows for efficient querying and analysis of log data. This article will cover how to configure DynamoDB for log storage, implement efficient query patterns for log analysis, and optimize DynamoDB for real-time data ingestion.
Setting Up DynamoDB for Log Storage
To store processed Kafka log data and anomaly detection results from SageMaker, you need to set up a DynamoDB table with a schema that supports efficient querying and scalability.
Table Schema Design
Each log entry should be stored with key attributes that allow for fast retrieval. Here’s an example schema:
Primary Key
A composite key consisting of logId (partition key) and timestamp (sort key).
Attributes
- logId: A unique identifier for the log entry.
- timestamp: The time the log was processed.
- anomalyScore: The anomaly score returned by SageMaker (optional, for anomaly detection).
- logData: The original log data (e.g., response time, status code, duration).
Example DynamoDB table creation using AWS CLI:
aws dynamodb create-table \
--table-name KafkaLogData \
--attribute-definitions \
AttributeName=logId,AttributeType=S \
AttributeName=timestamp,AttributeType=N \
--key-schema \
AttributeName=logId,KeyType=HASH \
AttributeName=timestamp,KeyType=RANGE \
--billing-mode PAY_PER_REQUEST
Data Insertion
After the DynamoDB table is created, the next step is to insert processed logs from Lambda. Each log, along with its associated metadata (e.g., anomaly scores from SageMaker), should be inserted into the DynamoDB table.
Example Lambda function for inserting log data into DynamoDB:
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('KafkaLogData')
def insert_log_to_dynamodb(log_id, timestamp, anomaly_score, log_data):
table.put_item(
Item={
'logId': log_id,
'timestamp': timestamp,
'anomalyScore': anomaly_score,
'logData': log_data
}
)
This function takes in log data, the anomaly score (if any), and metadata and stores it in the DynamoDB table.
def store_log_to_dynamo(log_message, rcf_score):
try:
# Get the DynamoDB table
table = dynamodb.Table(DYNAMO_TABLE_NAME)
# Prepare the log entry with the RCF score (convert floats to Decimal)
log_entry = {
'log_identifier': log_message['log_identifier'],
'timestamp': Decimal(str(log_message['timestamp'])),
'log_level': log_message['log_level'],
'ip_address': log_message['ip_address'],
'user_id': log_message['user_id'],
'method': log_message['method'],
'path': log_message['path'],
'status_code': log_message['status_code'],
'response_time': Decimal(str(log_message['response_time'])),
'message': log_message['message'],
'rcf_score': Decimal(str(rcf_score)) # Store exact score as Decimal
}
# Log the log_entry being written to DynamoDB
logger.info(f"Log entry being written to DynamoDB: {log_entry}")
# Write to DynamoDB
table.put_item(Item=log_entry)
logger.info("Log successfully written to DynamoDB")
except Exception as e:
logger.error(f"Error writing to DynamoDB: {str(e)}")
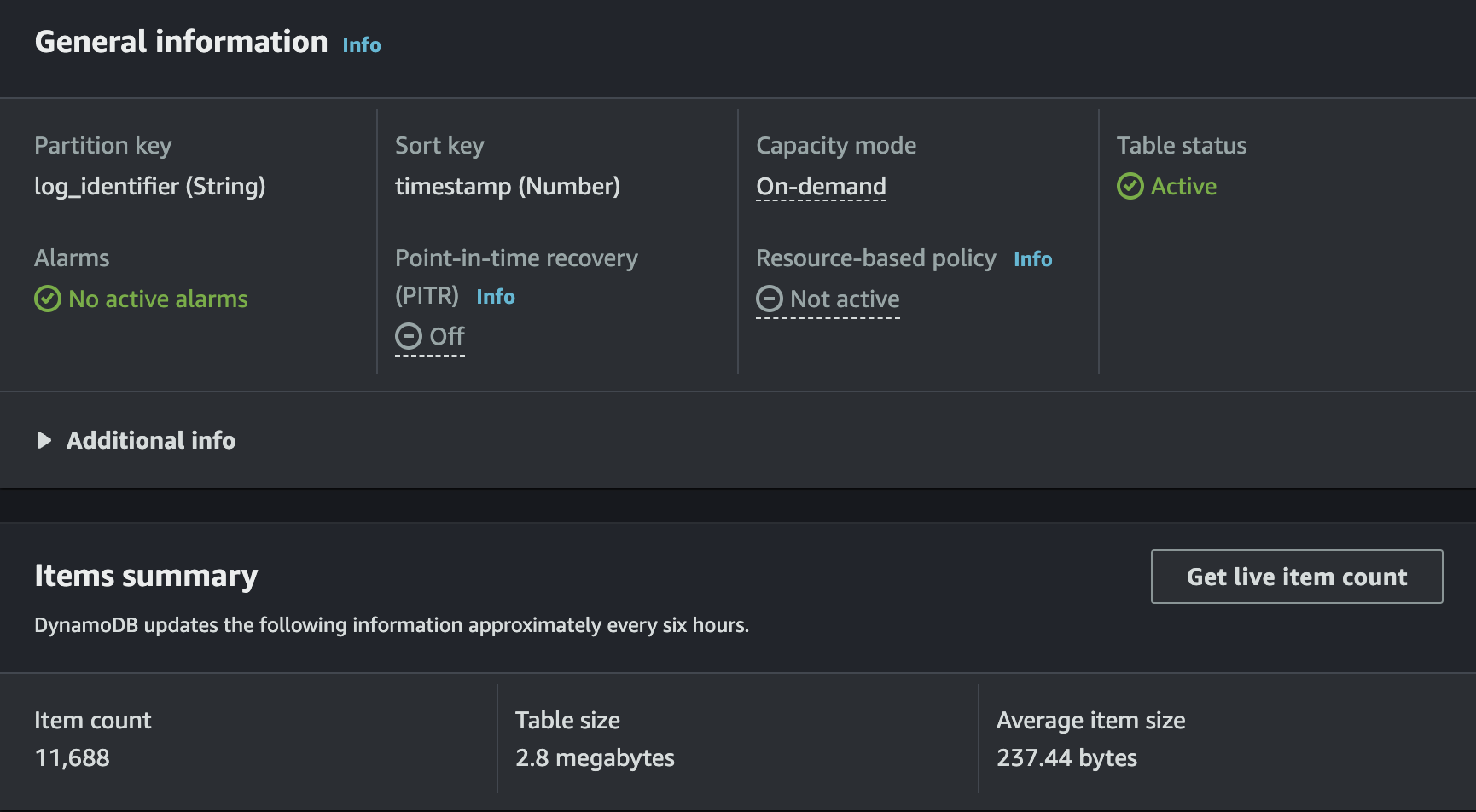
Querying DynamoDB for Log Analysis
One of DynamoDB’s strengths lies in its querying capabilities, allowing you to retrieve log data based on specific conditions efficiently. Here are some query patterns to consider when analyzing logs.
Querying by Time Range
Often, you’ll want to retrieve logs within a specific time range. Since timestamp is the sort key, you can perform a range query to retrieve logs processed during a given time window.
Example query to retrieve logs between two timestamps:
def query_logs_by_time_range(start_time, end_time):
response = table.query(
KeyConditionExpression='logId = :log_id AND #ts BETWEEN :start_time AND :end_time',
ExpressionAttributeValues={
':log_id': 'unique_log_id',
':start_time': start_time,
':end_time': end_time
},
ExpressionAttributeNames={
'#ts': 'timestamp'
}
)
return response['Items']
This query retrieves logs for a specific logId that fall between start_time and end_time.
Querying by Anomaly Score
You may want to query logs that have anomaly scores above a certain threshold to focus on outliers in the data. This requires creating a Global Secondary Index (GSI) on the anomalyScore attribute.
Create GSI using AWS CLI:
Copy code
aws dynamodb update-table \
--table-name KafkaLogData \
--attribute-definitions AttributeName=anomalyScore,AttributeType=N \
--global-secondary-index-updates \
"[{\"Create\":{\"IndexName\": \"AnomalyScoreIndex\", \"KeySchema\": [{\"AttributeName\":\"anomalyScore\",\"KeyType\":\"HASH\"}], \"ProvisionedThroughput\":{\"ReadCapacityUnits\": 10, \"WriteCapacityUnits\": 5}, \"Projection\":{\"ProjectionType\":\"ALL\"}}}]"
Query logs with high anomaly scores:
def query_logs_by_anomaly_score(min_score):
response = table.query(
IndexName='AnomalyScoreIndex',
KeyConditionExpression='anomalyScore >= :min_score',
ExpressionAttributeValues={
':min_score': min_score
}
)
return response['Items']
This query retrieves logs where the anomalyScore is greater than or equal to the specified threshold.
DynamoDB Optimization Strategies
As you scale your log processing pipeline, it’s essential to optimize DynamoDB for both real-time insertion and querying to avoid bottlenecks and ensure low-latency performance.
- Optimize Writes with Batch Operations When inserting large volumes of log data, use the batch_write_item API to optimize throughput and reduce the number of individual write requests.
Example of batch writing log data:
Copy code
def batch_insert_logs(log_items):
with table.batch_writer() as batch:
for item in log_items:
batch.put_item(Item=item)
- TTL for Expiring Logs Enable DynamoDB’s Time-to-Live (TTL) feature to automatically expire log records that are no longer needed. This helps reduce storage costs and keeps the table lean for faster queries.
Set TTL on the timestamp attribute:
aws dynamodb update-time-to-live \
--table-name KafkaLogData \
--time-to-live-specification "Enabled=true, AttributeName=timestamp"
This automatically deletes logs after a certain period, reducing the table size.
Key Takeaways
- Scalability: DynamoDB’s ability to automatically scale based on demand makes it ideal for real-time log storage in high-volume Kafka pipelines.
- Efficient Queries: By designing the table schema with appropriate partition and sort keys, and using GSIs, you can efficiently query logs based on time ranges and anomaly scores.
- Cost Optimization: Using features like on-demand mode, TTL, and batch operations helps optimize costs while maintaining performance at scale.
- Real-Time Log Processing: DynamoDB’s low-latency nature allows it to store and retrieve log data in real-time, making it a key component in serverless log processing architectures.
By leveraging DynamoDB for storing and querying Kafka log data, you can build a high-performance, scalable log processing system that efficiently handles real-time data. With proper schema design, query patterns, and optimizations, DynamoDB provides an excellent foundation for analyzing large volumes of log data.