
Introduction
When people talk about modernization, they often picture “lift and shift,” total rewrites, or big-bang digital transformation. But reality is messier. In most enterprises, legacy code like COBOL isn’t going anywhere—it still runs core business functions, and rewriting it is usually a non-starter. Instead, the smarter move is to wrap and extend it: containerize it, orchestrate it, observe it, and—yes—train machine learning models around it.
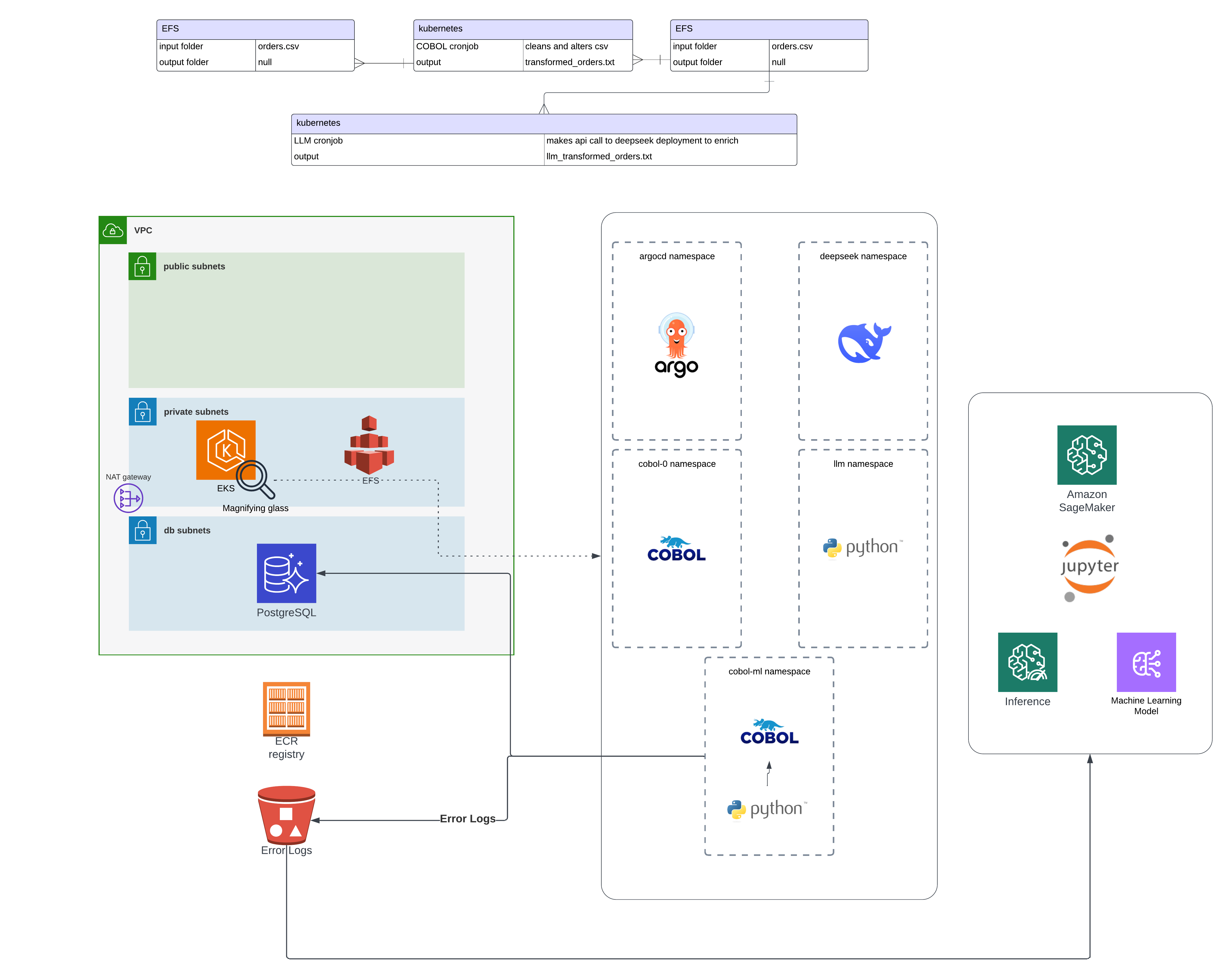
In this final article of the eks_cobol series, we’ll reflect on the architectural lessons, tech gotchas, and practical wins of combining COBOL, Kubernetes, and SageMaker. You’ll walk away with a blueprint for how to do it in your own environment—and where the landmines are buried.
Architectural Recap
Let’s start with what we built:
- COBOL on Kubernetes: We run GnuCOBOL inside containerized workloads, scheduled by K8s Jobs, with persistent shared storage via Amazon EFS.
- Structured Logging: STDOUT/STDERR logs are parsed and saved as JSON files in S3 for traceability and ML readiness.
- PostgreSQL Sink: Valid, enriched records are inserted into a relational store for downstream use.
- SageMaker Model: We trained an XGBoost model on historical failures to predict which jobs are likely to fail before execution.
- Feedback Loop: Inference scores now route high-risk files away from execution or into validation workflows.
It’s COBOL—but with an observability stack, proactive defense, and self-learning behavior.
Key Lessons Learned
1. Don’t Rewrite What Already Works
We didn’t rewrite COBOL. We containerized it. That’s a critical distinction. GnuCOBOL let us preserve decades of business logic while packaging it into a portable, observable runtime. By wrapping COBOL in Docker and invoking it via shell, we gained control without touching the legacy internals.
If the codebase is stable and correct, leave it alone. Modernize around it.
2. Logs Are a Goldmine—Structure Them
COBOL wasn’t built for structured logging. But by intercepting logs and shaping them into JSON, we unlocked a treasure trove of analytics possibilities. Every error, success, or anomaly became traceable, searchable, and ML-trainable.
Your pipeline is only as smart as your logs are readable.
3. Machine Learning Loves Legacy
This is not hype. ML is perfect for legacy systems because:
- It doesn’t require code access.
- It thrives on patterns and history.
- It improves incrementally.
Our failure prediction model now prevents bad jobs from ever running, saving compute time and protecting downstream systems.
4. Kubernetes Handles Legacy Workloads Surprisingly Well
Many assume Kubernetes is for stateless microservices only. Wrong. We used EFS + Jobs + taints/tolerations to isolate legacy workloads without sacrificing elasticity or modern DevOps practices.
Legacy ≠ incompatible. With the right node pools and volume setup, K8s handles batch, stateful, or weird workloads just fine.
5. Async Communication Is Essential
Each component of this pipeline operates independently:
- COBOL runs in isolation.
- Parsers and enrichers are microservices.
- ML runs out-of-band, in a parallel path.
S3, EFS, and event-driven messaging (SQS or Step Functions) glue the pieces together. That’s how we scale and decouple without breaking the whole thing.
Gotchas to Watch Out For
❌ Parsing COBOL Errors Is a Pain
You’ll spend way more time writing regex and building robust parsers than you’d like. COBOL errors weren’t designed to be machine readable. Build good test cases.
❌ Storage Permissions in K8s + EFS
Mounting EFS with the right IAM and access points requires some pain up front. Use the AWS EFS CSI driver and restrict access by namespace or workload label.
❌ Model Drift Can Sneak Up on You
As inputs evolve (new file formats, new job types), your ML model may lose accuracy. Schedule retraining and monitor for prediction distribution changes using SageMaker Model Monitor.
❌ Job Bloat If You Don’t Clean Up
Kubernetes Jobs can leave stale pods if not configured correctly. Use .spec.ttlSecondsAfterFinished or a custom controller to delete completed/failed jobs.
The Bigger Picture
This project isn’t just a modernization. It’s proof that:
- COBOL is not the enemy.
- Kubernetes isn’t just for Node.js and Python.
- Machine learning isn’t just for greenfield use cases.
You can combine old and new, determinism and prediction, batch and real-time. It’s not just technically feasible—it’s strategically smart. You protect your investment in legacy, while gaining all the advantages of modern infrastructure and AI.
Final Architecture Diagram
Conclusion
You don’t need to choose between rewriting everything or staying frozen in time. This series showed how to elevate COBOL with containers, orchestrators, log structure, and machine learning—all without rewriting core logic.
This hybrid approach isn't just a one-off—it's a repeatable strategy. Any legacy system that produces structured input/output can benefit from this architecture. You give it new life, visibility, and intelligence. And that makes your system—and your team—a lot smarter.