

AWS Lambda plays a pivotal role in serverless architectures, particularly for real-time data processing. It enables you to run code without provisioning or managing servers, allowing you to focus on building scalable, event-driven applications. In the context of log processing, Lambda can be triggered by streaming data sources like Amazon MSK (Managed Streaming for Apache Kafka) or Kafka topics running in your own environment on EKS. By integrating Lambda with Amazon SageMaker, you can process Kafka logs in real time and use machine learning models, such as Random Cut Forest (RCF), to score these logs for anomalies. In this article, we will explore how to configure Lambda to process Kafka logs, invoke SageMaker for anomaly detection, and optimize the performance of Lambda functions for large-scale log processing.
Triggering Lambda from Kafka
To process Kafka logs in AWS, you need to configure Lambda to be triggered by Kafka events. Lambda has built-in support for Amazon MSK, allowing it to consume messages directly from Kafka topics. If you're running Kafka on EKS, you can use a combination of custom triggers and AWS services to route Kafka messages to Lambda.
- Create an Event Source Mapping (for MSK) To process logs from Kafka, you need to set up an event source mapping that connects your Kafka topic to the Lambda function. This allows Lambda to be invoked whenever new log messages are published to the Kafka topic.
- Example of creating an event source mapping for MSK:
aws lambda create-event-source-mapping \
--function-name my-kafka-lambda \
--event-source-arn arn:aws:kafka:<region>:<account-id>:cluster/<cluster-name>/<cluster-arn> \
--batch-size 100 \
--starting-position LATEST \
--topics my-log-topic
This command sets up an event source mapping that invokes the Lambda function my-kafka-lambda when logs are published to the Kafka topic my-log-topic.
- Custom Trigger (what I did) If your Kafka cluster is running on EKS, you can route logs to Lambda by using an intermediary service like AWS Kinesis Data Streams or AWS S3. I wrote the logs directly to Lambda.
- Example of Kafka producer streaming to Kinesis:
import boto3
kinesis = boto3.client('kinesis')
def send_log_to_kinesis(log_data):
kinesis.put_record(
StreamName="kafka-log-stream",
Data=log_data.encode('utf-8'),
PartitionKey="log"
)
You can then set up a Lambda trigger to process these logs in real time.
Processing and Scoring Logs with SageMaker
Once the Kafka logs trigger the Lambda function, the next step is to process and score these logs using SageMaker. The Lambda function will invoke a SageMaker endpoint where an RCF (Random Cut Forest) model has been deployed for anomaly detection.
- Extracting and Preparing Log Data In the Lambda function, you first need to extract the relevant log data from the Kafka event. The logs can contain features such as response time, status code, and duration that need to be passed to SageMaker for scoring.
- Example Lambda function to extract log data:
import json
import boto3
sagemaker_runtime = boto3.client('runtime.sagemaker')
def lambda_handler(event, context):
# Extract logs from Kafka event
log_data = event['records'][0]['value']
log_features = parse_log_data(log_data)
# Prepare payload for SageMaker
payload = json.dumps([log_features])
# Invoke SageMaker endpoint
response = sagemaker_runtime.invoke_endpoint(
EndpointName="rcf-anomaly-endpoint",
ContentType="application/json",
Body=payload
)
# Parse the response to get the anomaly score
result = json.loads(response['Body'].read().decode())
anomaly_score = result['scores'][0]
# Take action based on anomaly score
if anomaly_score > 3.0:
print(f"Anomaly detected: {anomaly_score}")
else:
print(f"Normal log data: {anomaly_score}")
return {
'statusCode': 200,
'body': json.dumps({'anomaly_score': anomaly_score})
}
def parse_log_data(log_data):
# Parse the log data to extract features (response time, status code, etc.)
log_features = [0.45, 200, 1200] # Example: [response_time, status_code, duration]
return log_features
This function processes incoming logs, invokes the SageMaker endpoint, and logs the anomaly score.
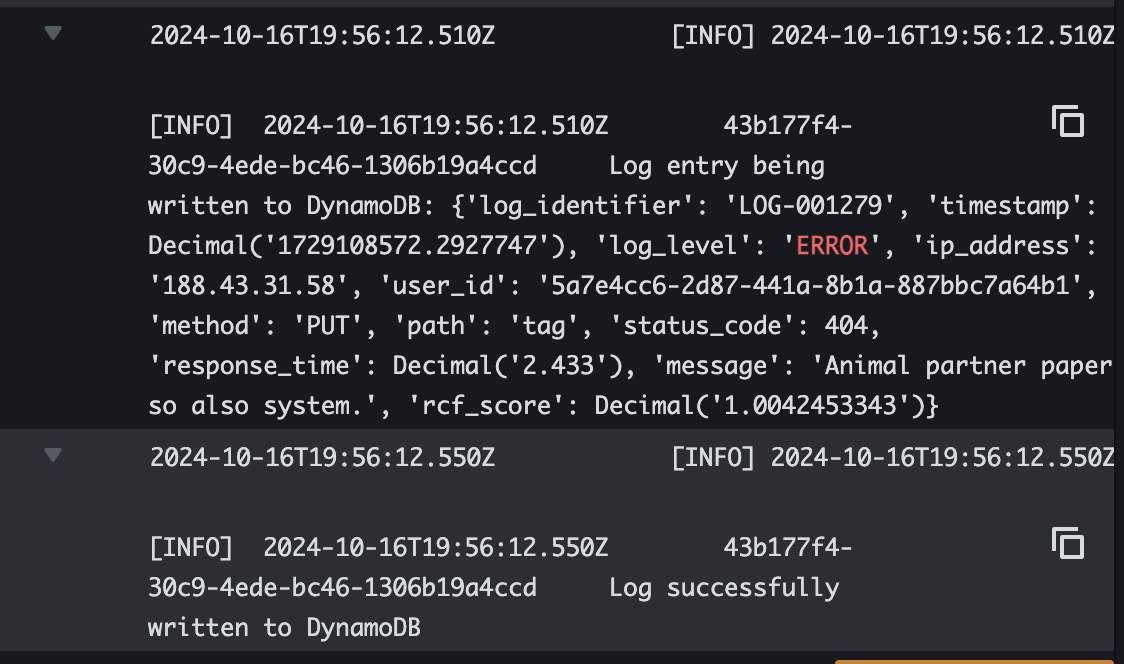
- Interpreting Anomaly Scores The response from SageMaker contains an anomaly score for each log entry. Scores above a certain threshold (e.g., 3.0) indicate anomalous behavior. You can configure the Lambda function to take different actions based on these scores, such as logging the anomaly, sending an alert, or storing the data in DynamoDB for further analysis.
'rcf_score': Decimal('1.0042453343')
Optimizing Lambda Performance
To handle large-scale log processing, it’s important to optimize Lambda’s performance, especially when integrating with external services like SageMaker.
- Batch Processing Lambda allows you to process Kafka logs in batches, which reduces the number of invocations and improves efficiency. You can configure the batch size in the event source mapping to optimize the trade-off between latency and throughput.
- Example of configuring batch size:
aws lambda update-event-source-mapping \
--uuid <mapping-id> \
--batch-size 500
A larger batch size reduces the number of invocations but increases latency.
- Concurrency Control Limit the concurrency of your Lambda function to prevent it from overwhelming downstream services, such as SageMaker or DynamoDB.
- Example of setting a concurrency limit:
aws lambda put-function-concurrency --function-name my-kafka-lambda --reserved-concurrent-executions 50
This command ensures that no more than 50 Lambda instances are running concurrently, preventing overloading of the SageMaker endpoint.
- Timeouts and Retries Configure appropriate timeouts and retries in your Lambda function to handle intermittent failures or delays in response from the SageMaker endpoint.
- Example Lambda configuration:
aws lambda update-function-configuration \
--function-name my-kafka-lambda \
--timeout 30 \
--memory-size 1024
Increasing memory size and timeout ensures that the function has enough resources to handle large batches of logs.
Key Takeaways
- Event-Driven Architecture: AWS Lambda is ideal for event-driven architectures, making it perfect for real-time log processing in serverless environments.
- Real-Time Scoring: By integrating Lambda with SageMaker, you can score Kafka logs in real-time for anomaly detection, allowing you to catch issues as they occur.
- Scalability: Lambda’s ability to automatically scale based on incoming Kafka logs ensures that your log processing pipeline can handle massive volumes of data without manual intervention.
- Performance Optimization: Batch processing, concurrency limits, and memory management are key to ensuring that Lambda performs efficiently in large-scale log processing scenarios.
Using AWS Lambda for processing Kafka logs allows you to build a scalable, event-driven log processing system that leverages the power of machine learning with SageMaker for real-time anomaly detection. By optimizing Lambda’s performance and carefully tuning your configurations, you can build a cost-effective and robust solution for log analysis.
Log successfully written to DynamoDB