

Overview
This article covers the initial infrastructure setup for deploying a churn prediction model in Google Cloud Platform (GCP) using BigQuery ML. The objective for the customer is to set up an infrastructure that allows seamless data storage, model training, and evaluation within GCP, with all configurations managed through Terraform. This approach ensures reproducibility, consistent deployment, and efficient resource management.
BigQuery Dataset Creation
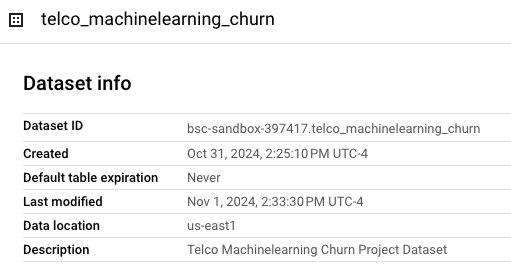
The next step involves creating a BigQuery dataset to store churn data and model artifacts. This dataset will be where we conduct data processing, model training, and results storage.
Dataset Creation Snippet
resource "google_bigquery_dataset" "churn_dataset" {
dataset_id = var.project
friendly_name = var.project
description = "${title(replace(var.project, "_", " "))} Project Dataset"
location = var.region
labels = var.labels
access {
role = "OWNER"
user_by_email = google_service_account.sa.email
}
access {
role = "OWNER"
user_by_email = data.google_client_openid_userinfo.caller_info.email
}
}
Explanation
- dataset_id: Unique identifier for the dataset, typically matching the project name.
- friendly_name: A human-readable name for the dataset.
- description: Provides a description for better documentation and tracking.
- access: Configures access permissions. Here, we give OWNER permissions to a service account and the current user, following least-privilege access control.
BigQuery is ideal for this project because it is a fully managed data warehouse, providing high-performance analytics on large datasets. By creating a BigQuery dataset, we centralize data storage and model artifacts for the churn prediction model. With this setup:
- Efficiency: Data remains within GCP, reducing data transfer costs and latency.
- Scalability: BigQuery handles large datasets effectively, which is crucial as telecom data often grows quickly.
- Integration with BigQuery ML: We can run machine learning models directly within the data warehouse, simplifying the process and reducing the need for external ML infrastructure.
The dataset creation step includes configuring access control to enforce least-privilege permissions, limiting access only to those with specific roles, and thus enhancing security.
Setting Up Cloud Storage
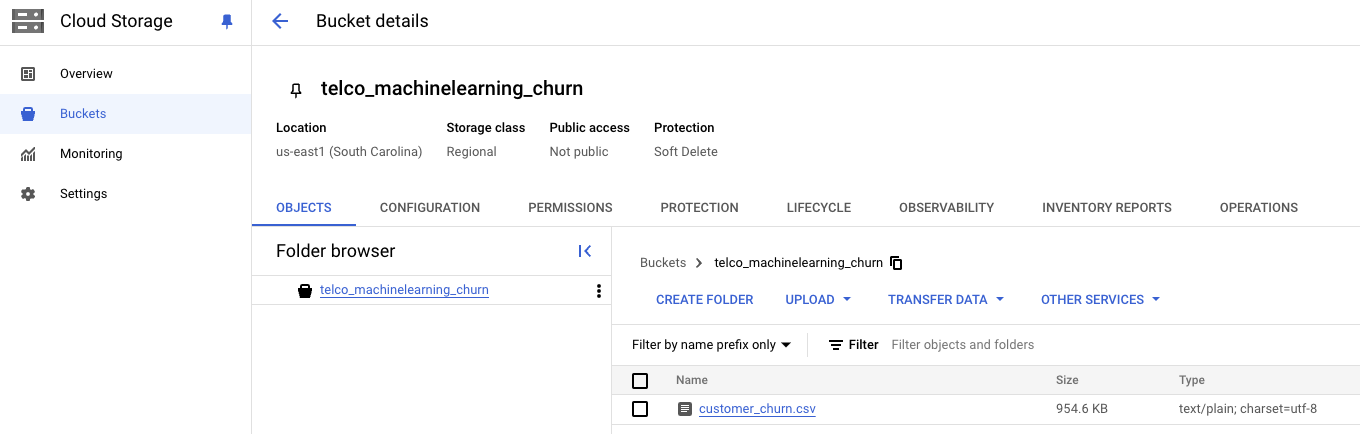
We need a GCS bucket to store raw customer churn data in CSV format, which BigQuery will later access. The bucket will serve as a central repository for input data and provide the flexibility for batch uploads or scheduled imports.
Cloud Storage Bucket Configuration Snippet
resource "google_storage_bucket" "data_bucket" {
name = var.project
location = var.region
public_access_prevention = "enforced"
storage_class = "REGIONAL"
labels = var.labels
}
Explanation
- name: Specifies the bucket name, typically the project name for consistency.
- public_access_prevention: Ensures data in the bucket is not publicly accessible, enhancing security.
- storage_class: Uses a REGIONAL class for optimized, low-latency access.
For handling raw data, Google Cloud Storage is used as a data lake to store CSV files. GCS offers:
- Secure, Scalable Storage: GCS can handle large datasets, and its regional storage class optimizes access and cost.
- Easy Integration with BigQuery: We can load data directly from GCS into BigQuery, eliminating the need for data transfer pipelines and improving processing efficiency.
- Cost Management: Storing raw data in GCS allows BigQuery to access it on demand, minimizing unnecessary storage costs in BigQuery itself.
GCS also supports access control policies, allowing us to configure public access prevention and enforce security policies.
IAM Roles and Permissions
To ensure secure and controlled access, we assign IAM roles to resources and service accounts with a least-privilege approach. Roles are granted specifically to support BigQuery access, storage management, and dataset operations.
IAM Configuration Snippet
resource "google_service_account" "sa" {
account_id = replace(var.project, "_", "-")
display_name = "${var.project} Service Account"
}
resource "google_project_iam_member" "bigquery_access" {
project = var.project
role = "roles/bigquery.dataEditor"
member = "serviceAccount:${google_service_account.sa.email}"
}
resource "google_project_iam_member" "storage_access" {
project = var.project
role = "roles/storage.objectAdmin"
member = "serviceAccount:${google_service_account.sa.email}"
}
Explanation
- google_service_account: Creates a service account to manage resources.
- google_project_iam_member: Grants BigQuery Data Editor and Storage Object Admin roles to the service account. This ensures it has only the necessary permissions to edit BigQuery data and manage GCS storage.
A crucial step in any cloud deployment is defining IAM roles and permissions to ensure secure access to resources. Using IAM:
- Role-Based Access: We assign specific roles to the service account based on the principle of least privilege. This limits access to only the resources required for model training, reducing security risks.
- Granular Control: By granting the service account BigQuery Data Editor and Storage Object Admin roles, we ensure it can only interact with BigQuery and GCS as needed, minimizing exposure to other services.
- Flexibility: These IAM roles can be modified and extended if other GCP services are added in the future.
This setup ensures that access to customer data and model results is tightly controlled, adhering to security best practices.
These configurations lay the foundation for building and deploying the churn prediction model in Google Cloud. With Terraform, this infrastructure can be replicated across environments, facilitating consistent and secure deployment for future projects.