

Modernizing legacy COBOL applications is the start for organizations aiming to enhance scalability, maintainability, and integration within modern cloud-native ecosystems. By containerizing COBOL applications and deploying them as Kubernetes CronJobs, businesses can achieve these goals efficiently. This guide provides a detailed walkthrough on how to containerize a COBOL application and run it within a Kubernetes environment.
Prerequisites
Before proceeding, ensure you have the following:
- COBOL Source Code: Access to the COBOL application you intend to containerize.
- Docker: Installed on your local machine for building container images.
- Kubernetes Cluster: An operational cluster where you have deployment permissions.
- kubectl: Configured to interact with your Kubernetes cluster.
- Helm: Installed for managing Kubernetes applications.
Step 1: Containerizing the COBOL Application
Begin by creating a Docker image for your COBOL application. We'll use GnuCOBOL, an open-source COBOL compiler, to compile and run the application within the container.
Dockerfile:
FROM ubuntu:22.04
RUN apt-get update && apt-get install -y \
gnucobol \
gcc \
&& apt-get clean
WORKDIR /app
COPY TransformCSV.cbl /app/
COPY run.sh /app/
RUN chmod +x /app/run.sh
ENTRYPOINT ["/app/run.sh"]
In this Dockerfile:
- We start with the official Ubuntu 22.04 image.
- Install GnuCOBOL and GCC.
- Set the working directory to
/app. - Copy the COBOL source code (
TransformCSV.cbl) and the shell script (run.sh) into the container. - Make the
run.shscript executable. - Define the entry point to execute the
run.shscript.
Shell Script (run.sh):
#!/bin/bash
set -x
cobc -x -free TransformCSV.cbl -o TransformCSV
./TransformCSV
This script compiles the TransformCSV.cbl COBOL program and executes the resulting binary.
COBOL Program (TransformCSV.cbl):
IDENTIFICATION DIVISION.
PROGRAM-ID. TransformCSV.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT InputFile ASSIGN TO "/mnt/efs/input/orders.csv"
ORGANIZATION IS LINE SEQUENTIAL.
SELECT OutputFile ASSIGN TO "/mnt/efs/output/transformed_orders.txt"
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD InputFile.
01 InputRecord.
05 OrderID PIC X(4).
05 Comma1 PIC X.
05 CustomerName PIC X(20).
05 Comma2 PIC X.
05 AddressField PIC X(20).
05 Comma3 PIC X.
05 Item PIC X(10).
05 Comma4 PIC X.
05 Amount PIC X(3).
05 Comma5 PIC X.
05 PurchaseFrequency PIC X(2).
FD OutputFile.
01 OutputRecord PIC X(100).
WORKING-STORAGE SECTION.
01 WS-EOF PIC X VALUE 'N'.
PROCEDURE DIVISION.
MainSection.
OPEN INPUT InputFile
OPEN OUTPUT OutputFile
PERFORM UNTIL WS-EOF = 'Y'
READ InputFile
AT END
MOVE 'Y' TO WS-EOF
NOT AT END
PERFORM TransformRecord
END-READ
END-PERFORM
CLOSE InputFile
CLOSE OutputFile
STOP RUN.
TransformRecord.
MOVE SPACES TO OutputRecord
STRING "Order: ", OrderID, " | ",
CustomerName, " | ",
AddressField, " | ",
Item, " | ",
Amount, " | Frequency: ",
PurchaseFrequency
INTO OutputRecord
ON OVERFLOW DISPLAY "Error writing record."
END-STRING
WRITE OutputRecord.
This COBOL program reads an orders.csv file, processes each record, and writes the transformed data to transformed_orders.txt.
Building the Docker Image:
Navigate to the directory containing your Dockerfile, COBOL source code, and shell script, then build the Docker image:
docker build -t cobol-app:latest .
Step 2: Deploying the COBOL Application on Kubernetes
To run the COBOL application as a scheduled task, we'll deploy it using a Kubernetes CronJob. Additionally, we'll set up persistent storage using Amazon Elastic File System (EFS) to handle input and output files.
Helm Chart Configuration:
We'll use Helm to manage the deployment. Create a Helm chart with the following structure:
apiVersion: v1
kind: Namespace
metadata:
name: {{ .Values.cobol0.name }}
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: {{ .Values.cobol0.name }}-pv
namespace: {{ .Values.cobol0.name }}
spec:
capacity:
storage: {{ .Values.cobol0.storage.size }}
volumeMode: Filesystem
accessModes:
{{ toYaml .Values.cobol0.storage.accessModes | indent 4 }}
persistentVolumeReclaimPolicy: {{ .Values.cobol0.storage.reclaimPolicy }}
storageClassName: {{ .Values.cobol0.storage.storageClassName }}
csi:
driver: efs.csi.aws.com
volumeHandle: {{ .Values.cobol0.storage.volumeHandle }}
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: {{ .Values.cobol0.name }}-pvc
namespace: {{ .Values.cobol0.name }}
spec:
accessModes:
{{ toYaml .Values.cobol0.storage.accessModes | indent 4 }}
resources:
requests:
storage: {{ .Values.cobol0.storage.size }}
storageClassName: {{ .Values.cobol0.storage.storageClassName }}
---
apiVersion: batch/v1
kind: CronJob
metadata:
name: {{ .Values.cobol0.name }}-cronjob
namespace: {{ .Values.cobol0.name }}
spec:
schedule: "* * * * *"
concurrencyPolicy: Replace
jobTemplate:
spec:
template:
spec:
restartPolicy: Never
activeDeadlineSeconds: 30
containers:
- name: {{ .Values.cobol0.name }}-container
image: "{{ .Values.cobol0.image.repository }}:{{ .Values.cobol0.image.tag }}"
imagePullPolicy: {{ .Values.cobol0.image.pullPolicy }}
env:
- name: INPUT_FILE
value: "{{ .Values.cobol0.environment.INPUT_FILE }}"
- name: OUTPUT_FILE
value: "{{ .Values.cobol0.environment.OUTPUT_FILE }}"
volumeMounts:
- name: efs-volume
mountPath: /mnt/efs
resources:
requests:
cpu: "{{ .Values.cobol0.resources.requests.cpu }}"
memory: "{{ .Values.cobol0.resources.requests.memory }}"
limits:
cpu: "{{ .Values.cobol0.resources.limits.cpu }}"
memory: "{{ .Values.cobol0.resources.limits.memory }}"
volumes:
- name: efs-volume
persistentVolumeClaim:
claimName: {{ .Values.cobol0.name }}-pvc
nodeSelector:
gpu: {{ .Values.cobol0.nodeSelector.gpu | quote }}
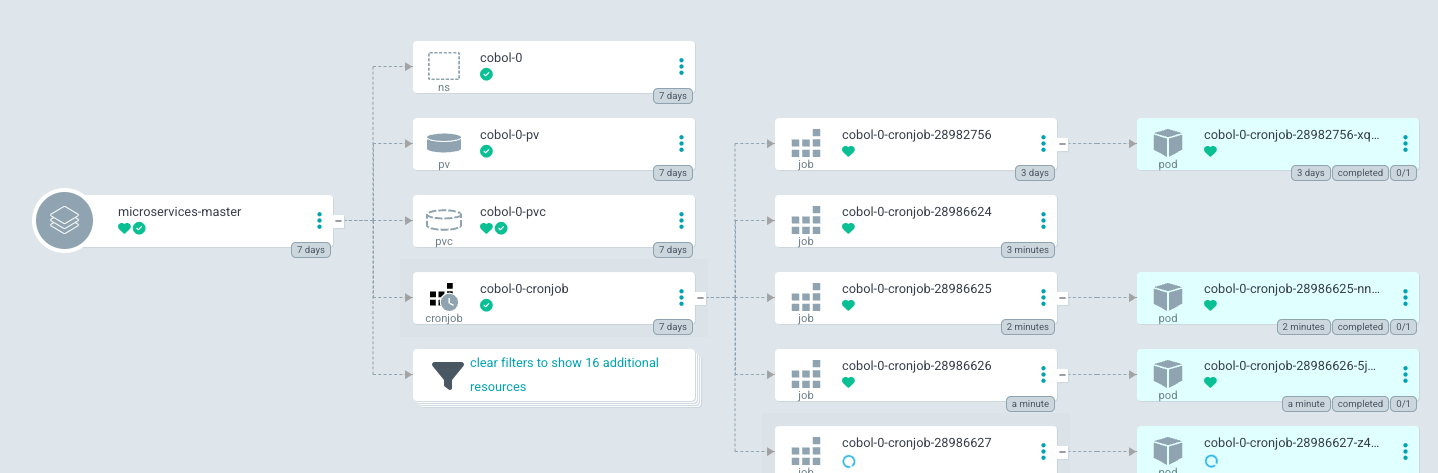
k logs -n cobol-0 cobol-0-cronjob-28986627-z4kb2
+ cobc -x -free TransformCSV.cbl -o TransformCSV
+ ./TransformCSV
Transitioning legacy COBOL applications into containerized environments orchestrated by Kubernetes offers a robust pathway for modernizing enterprise IT infrastructure. This approach not only preserves the functional integrity of mission-critical systems but also enhances scalability, maintainability, and integration with contemporary cloud-native services.
By following the steps outlined—containerizing the COBOL application, setting up persistent storage with Amazon EFS, and deploying the application as a Kubernetes CronJob—organizations can effectively bridge the gap between traditional mainframe systems and modern computing paradigms. This integration facilitates automated, scheduled processing of COBOL workloads, ensuring consistent performance and reliability.
Embracing this modernization strategy enables enterprises to reduce dependence on outdated mainframe hardware, optimize resource utilization, and position themselves to leverage advancements in cloud technologies and DevOps practices. As the technological landscape continues to evolve, such adaptability becomes crucial for maintaining competitive advantage and fostering innovation.
Containerizing COBOL applications and deploying them within a Kubernetes framework represents a forward-thinking solution to legacy system modernization, aligning with industry best practices and future-proofing organizational IT capabilities.