

Turning Hype into Reliable Enterprise ROI
Executive summary
Enterprises have moved rapidly from experimenting with generative AI to embedding it into core workflows. Adoption is high, however, impact is not. Many organizations have dozens of pilots, a handful (if any) of tactical wins, and very few production systems that consistently impact the bottom line.
One pattern is emerging among the companies that are seeing results: their most effective AI solutions still look more like applications than autonomous “intelligence.”
In this article, we describe an application-first approach to agentic AI, illustrated through a production-grade sprint-intelligence system that analyzes software delivery data across multiple code repositories. The system is designed so that:
- Most of the behavior is deterministic application logic.
- Agentic AI is used only to interpret grey areas: synthesizing, explaining, and contextualizing.
- Hallucinations are structurally constrained rather than “prompted away.”
- The result is a repeatable, auditable, and business-ready AI capability.
The same architecture pattern can be applied to many domains where enterprises need insight, not spectacle: operations, compliance, risk, engineering, and customer experience.
AI has scaled, impact has not
In a few years, AI has moved from fringe to mainstream. Boards ask about AI strategy in every quarterly review. Most large enterprises now report:
- Multiple AI or genAI use cases live in production.
- New budget lines dedicated to AI platforms, models, and infrastructure.
- Rapid experimentation in functions such as software engineering, customer service, marketing, and operations.
Yet when leaders examine hard financial metrics, such as, productivity, cost, revenue, risk, the story is often very different. A small subset of use cases deliver clear, repeatable value, while most remain stuck at pilot scale or under strict “sandbox” constraints.
Three themes recur in conversations with technology and business leaders:
- Trust – Experts do not fully trust AI outputs without human review.
- Consistency – The same prompt can yield different answers, breaking downstream automation.
- Compliance – Risk, audit, and regulatory teams struggle to sign off on opaque systems.
The result is a paradox: organizations spend more on AI each year, but have trepidation about letting it sit on the critical path of their business processes.
Why generic LLM solutions stall
Most stalled AI efforts share a recognizable pattern.
-
The model is the system.
The solution is designed “model-first”: a large language model sits at the center, with a thin wrapper of scripts and UI. Business logic is encoded inside prompts and few-shot examples. -
No deterministic backbone.
There is no clear separation between what must be exact (data retrieval, workflow steps, policy enforcement) and what can be approximate (narrative wording, prioritization, tone). -
Unbounded reasoning.
The model is asked to decide everything: how to interpret data, which steps to perform, what to call, and how to present results. Guardrails are mostly linguistic (“don’t hallucinate”) rather than structural. -
Limited observability.
It is hard to explain why the system gave a particular answer, what data it used, or how it flowed through the process. This makes it difficult to test, monitor, and improve.
In regulated environments, these weaknesses are unacceptable. Systems that cannot be audited, tested, or reliably reproduced cannot sit at the core of risk, finance, compliance, or mission-critical engineering workflows.
The question becomes: How can organizations benefit from AI’s reasoning and summarization capabilities without giving up control, determinism, and auditability?
Application-first agentic AI
A growing class of successful enterprise implementations adopts a different design principle:
Treat AI as a component inside a well-engineered application, not as the application itself.
In practice, this looks like:
-
A deterministic backbone
The end-to-end workflow—what data to pull, which steps to run, in what sequence—is fully defined in application code and orchestration logic. It is testable without any AI present. -
Agentic AI for grey areas only
AI is not used to decide what to do; it is used to decide how to describe, interpret, or prioritize things within clearly defined boundaries. Interpretation, not orchestration. -
Explicit roles and tools for agents
Each agent has a narrow mandate (for example, “analyze a single pull request,” “summarize sprint themes,” “draft an executive narrative”), along with a constrained toolset and input schema. -
Tight integration with enterprise architecture
The system leverages standard cloud primitives (serverless compute, storage, workflow engines, identity, and secrets management) so it can be deployed, monitored, and governed like any other production service.
The remainder of this article uses one concrete implementation—an agentic sprint-intelligence system for engineering leaders—to show what this pattern looks like in practice.
Case example
Agentic AI for sprint intelligence
Business problem
Visibility into software delivery
Modern development organizations operate across hundreds or thousands of repositories, tens of thousands of pull requests, and globally distributed teams. Engineering leaders and product owners need to answer questions such as:
- What actually shipped this sprint?
- Where did the team spend time: features, tech debt, reliability, experiments?
- Which patterns are emerging in quality, review discipline, or team collaboration?
- How do we communicate meaningful progress to executives without manually reading every pull request?
Today, answering these questions typically involves:
- Manually scanning a sample of pull requests.
- Asking team members to summarize their own work.
- Producing slide decks or written updates under time pressure.
- Accepting that much of the nuance will be lost.
The cost is not just time. It is missed insight. Patterns in architecture decisions, quality risks, and team dynamics are buried in unstructured code review history and never surface.
Solution overview
An agentic sprint-intelligence system
The sprint-intelligence system is designed to solve this problem with minimal human effort:
- A user specifies a date range and a set of repositories.
- The system autonomously:
- Discovers and validates repositories.
- Fetches all merged pull requests in the period.
- Gathers diffs, comments, reviews, and contextual files such as READMEs.
- Analyzes each pull request with specialized AI agents.
- Aggregates findings into a sprint-level narrative and metrics.
- The user receives an executive-ready sprint report in a browser, with clear traceability back to the underlying pull requests.
Crucially, the autonomy lies in how the system analyzes and synthesizes information, not in what it is allowed to do. The workflow itself is completely deterministic.
How the system works
Application first, agents on top
Deterministic workflow orchestration
At the core is a serverless workflow orchestrated by a cloud-native state machine (for example, AWS Step Functions). The orchestrator:
- Accepts input (date range, repositories) via an API.
- Decomposes the work into discrete steps.
- Executes those steps in parallel where possible.
- Handles retries, error handling, and timeouts.
- Ensures all operations are logged and auditable.

Every state in the workflow has a clearly defined contract: input shape, processing logic, and output shape. None of this depends on AI.
Application agents
The structured work
Most of the system’s behavior is implemented as “application agents”—specialized, non-AI functions that perform concrete tasks, such as:
- Parsing and normalizing repository URLs.
- Calling the GitHub API to list pull requests for a date range.
- Retrieving diffs, comments, reviews, and metadata.
- Computing basic statistics (number of PRs, cycle time, review depth).
- Chunking and summarizing large payloads to stay within size limits.
- Storing intermediate artefacts in object storage for later retrieval.
These agents are stateless, idempotent, and testable with traditional unit and integration tests. They ensure that the system always works with accurate, well-structured inputs before any AI model is invoked.
AI agents - the expert reviewers
Once the data is prepared, a fleet of AI agents—each backed by a large language model—performs the interpretive work.
-
Pull-request analyst agent
Acts as a senior engineer reviewing a single pull request. Given diffs, comments, and metadata, it:- Explains what changed and why.
- Identifies technical risk or complexity.
- Classifies the change (feature, bug fix, refactor, platform work).
- Assesses potential impact on performance, reliability, or security.
-
Sprint synthesis agent
Consumes the set of pull-request analyses and:- Identifies cross-cutting themes (for example, “focus on observability and reliability work this sprint”).
- Highlights notable contributions and risks.
- Suggests areas for follow-up in the next sprint.
- Produces an executive-level narrative in structured markdown.
These agents operate within strict boundaries:
- They receive structured, curated inputs from application agents.
- They are asked to answer specific questions in fixed formats.
- They cannot call arbitrary tools or modify the workflow.
- Their outputs are validated for schema conformance before downstream use.
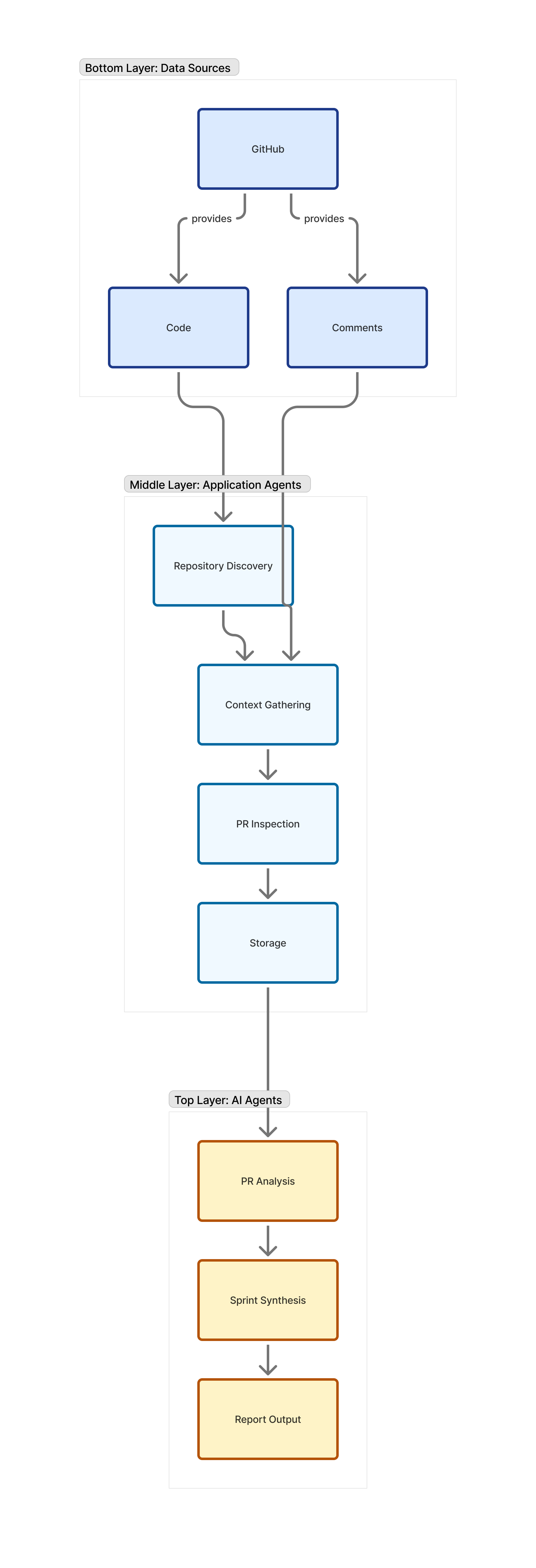
Architecture
Serverless and observable
The system is deployed as a fully serverless stack, typically including:
- Multiple specialized functions for the different agents.
- A workflow orchestrator to coordinate sequencing and parallelism.
- A managed AI service for model access.
- Object storage for analyses and reports.
- An API gateway fronting the backend.
- A static web frontend hosted on a content delivery network.
- A secrets manager for tokens and keys.
- Centralized logging and metrics via cloud monitoring tools.
This architecture offers:
- Elastic scaling with no server management.
- Clear cost visibility per execution and per sprint analysis.
- Unified logs for every state transition, enabling tracing from user request to final report.
Why hallucinations are structurally constrained
By design, the system minimizes opportunities for hallucination and uncontrolled behavior.
-
The model never “goes looking for data.”
All data is retrieved and preprocessed by application agents. The AI never fabricates sources because it is never asked to retrieve them. -
Questions are narrow and grounded.
Agents are asked specific questions about known artefacts (“Explain the impact of this diff and set of comments”) rather than open-ended ones (“What happened this sprint?”). -
Output formats are tightly specified.
Responses are expected in structured JSON or constrained markdown sections. If the schema is not met, the system can re-invoke the agent or flag the result. -
No agent controls the workflow.
Orchestration is performed by the state machine, not by any model. Agents cannot decide which step comes next, which APIs to call, or which data to fetch. -
Traceability is built-in.
Every generated insight points back to underlying pull requests and analyses. Human reviewers can easily verify the reasoning chain.
Put simply: hallucinations are not “discouraged” through prompting; they are made structurally hard to introduce.
Business impact
Beyond engineering dashboards
Although the sprint-intelligence example is rooted in software engineering, the underlying pattern matters for broader enterprise AI strategy.
This type of system can:
-
Reduce manual reporting workload.
Engineering managers and tech leads spend less time compiling updates and more time making decisions. -
Improve decision quality.
Leaders gain a holistic view of what actually shipped, where complexity is accumulating, and where to invest next. -
Create a reusable AI capability.
The same agentic architecture can be reused for compliance reports, operational logs, customer interactions, and other domains. -
Increase trust in AI.
Experts can see exactly how the system arrived at its conclusions, lowering the barrier to adoption.
Most importantly, the solution behaves like enterprise software:
- It can be tested, versioned, and rolled back.
- It has clear SLAs, error handling, and monitoring.
- It integrates with existing identity, security, and deployment practices.
This is what turns AI from an experiment into an operational asset.
What technology leaders should do now
For CIOs, CTOs, and Chief AI Officers looking to move from AI experimentation to durable business value, several practical steps emerge from this pattern.
-
Start with a real workflow, not a model.
Choose a concrete, recurring process where knowledge workers spend significant time aggregating and interpreting information (for example, sprint reviews, risk summaries, vendor assessments). Map it end-to-end without AI. -
Separate the exact from the approximate.
Clearly identify:- Steps that must be deterministic (data retrieval, policy checks, calculations).
- Steps where interpretation, summarization, or prioritization are acceptable.
-
Design an application-first architecture.
Build a backbone using established cloud primitives: APIs, workflow engines, functions, storage, and identity. Ensure the system makes sense and delivers some value even with AI disabled. -
Introduce agentic AI only where it adds leverage.
Insert agents to:- Explain complex artefacts in natural language.
- Synthesize themes across many items.
- Draft narratives or recommendations for human review.
-
Constrain agents with roles, schemas, and contracts.
Define for each agent:- A narrow role and perspective.
- Allowed inputs and required outputs.
- Guardrails on tone, scope, and behavior.
-
Invest early in observability and governance.
Treat the agentic system like any critical enterprise application:- Version control for prompts and workflows.
- Logging for every invocation and decision.
- Access control and data minimization by default.
-
Scale through reusable patterns, not one-off pilots.
Once the architecture works in one domain (such as sprint intelligence), replicate the pattern across other knowledge workflows. Reuse the orchestrator, agent templates, and deployment model.
Final Thoughts
Enterprises do not need more “AI demos.” They need AI systems that behave like robust software: predictable, testable, auditable, and aligned with how the business actually works.
Application-first agentic AI, where most of the intelligence lies in deterministic architecture, and models are used sparingly to interpret grey areas, offers a pragmatic path forward. The sprint-intelligence system described here is one example of what this looks like in production: a fully autonomous AI capability that still operates within the firm’s existing engineering, risk, and compliance guardrails.
As organizations move from pilots to platforms, the differentiator will not be who has access to the most powerful model, but who can design the most disciplined, application-centric systems around those models.
The winners will be those that treat AI not as a magic brain, but as a specialized component inside carefully engineered, business-critical applications.