Making PDFs Searchable Using AWS Textract and CloudSearch
If you have PDFs and want to make them searchable, provide the search functionality on your website or for internal use. This is what we are doing today...
Mahmood
2024-06-25
If you have PDFs and want to make them searchable, provide the search functionality on your website or for internal use. This is what we are doing today using AWS Textract and CloudSearch.
Why Textract? Will it is better than your average PDF-to-text extractor. Textract uses Machine Learning (ML) and Optical Character Recognition (OCR).
Why CloudSearch? There is no specific reason other than making it easy to search. You can use many other databases like MySQL, Postgres, MongoDB, etc.
Start by cloning the Terraform repo that sets up all your resources.
git clone https://github.com/mahmoodr786/aws-pdf-search.git
cd aws-pdf-search
terraform init
terraform apply
The repo has no-nonsense straight-up Terraform with everything main.tf file. Update the file with your bucket name, or change names around. You will also find the Python code needed to aid the search and move extracted text from S3 to CloudSearch. Here is a basic diagram to help you understand flow visually.
NOTE: I'm using very open permission on the Terraform as this is just a POC and will be destroyed. Please adjust your IAM permission to the least privileges.
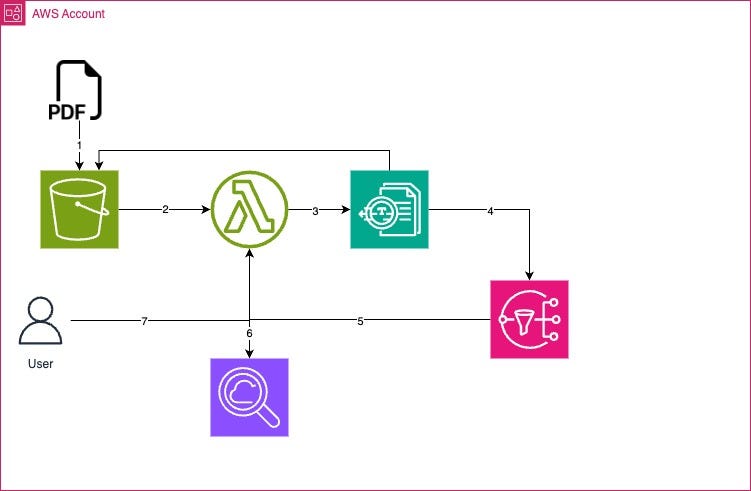
You start by uploading your PDFs in the S3 bucket in the pdfs folder/prefix. That will automatically trigger the Lambda function using S3 notification, and the Lambda will submit the PDF to AWS Textract. Once Textract is done, it will send a notification via SNS, which will trigger the same Lambda again, and the Python code will get all the files and lines of text from JSON files. Once it has all the text, it will be uploaded to CloudSearch. Finally, we use the same Lambda using function URL to search for PDFs that contain the keywords.
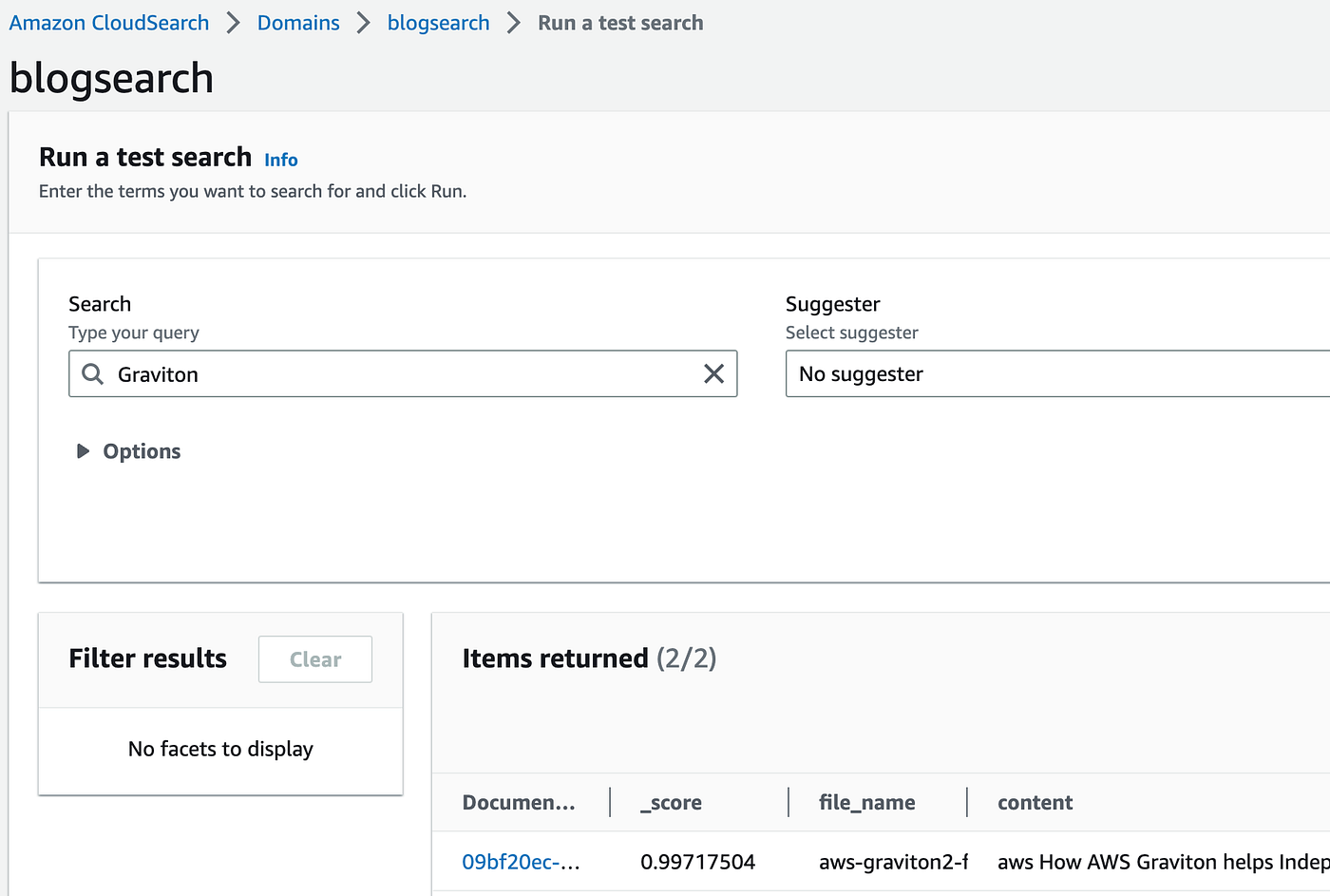
We are going to search for the keyword below from the Graviton2 Whitepaper.


Example search URL:
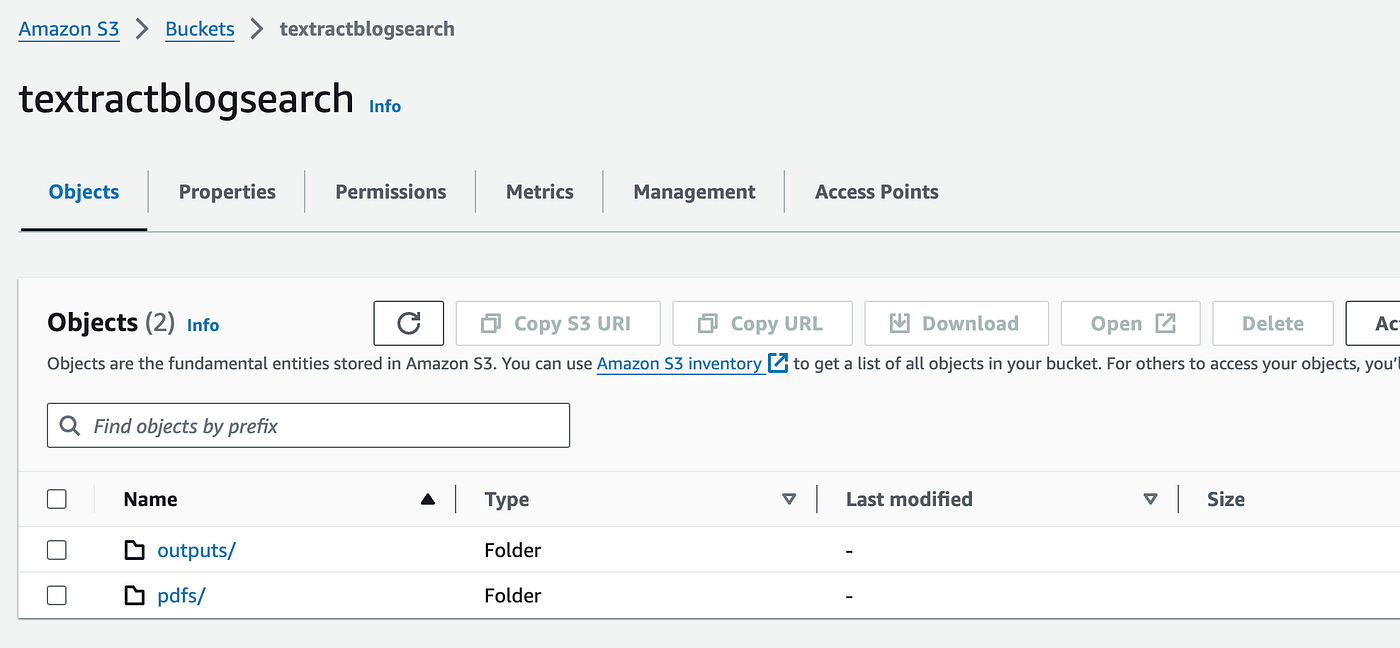
Once the Terraform is completed, you should see an S3 bucket create a prefix/folder called pdfs and begin uploading pdfs. The outputs folder is where Textract will dump the JSON files with text lines from PDF.
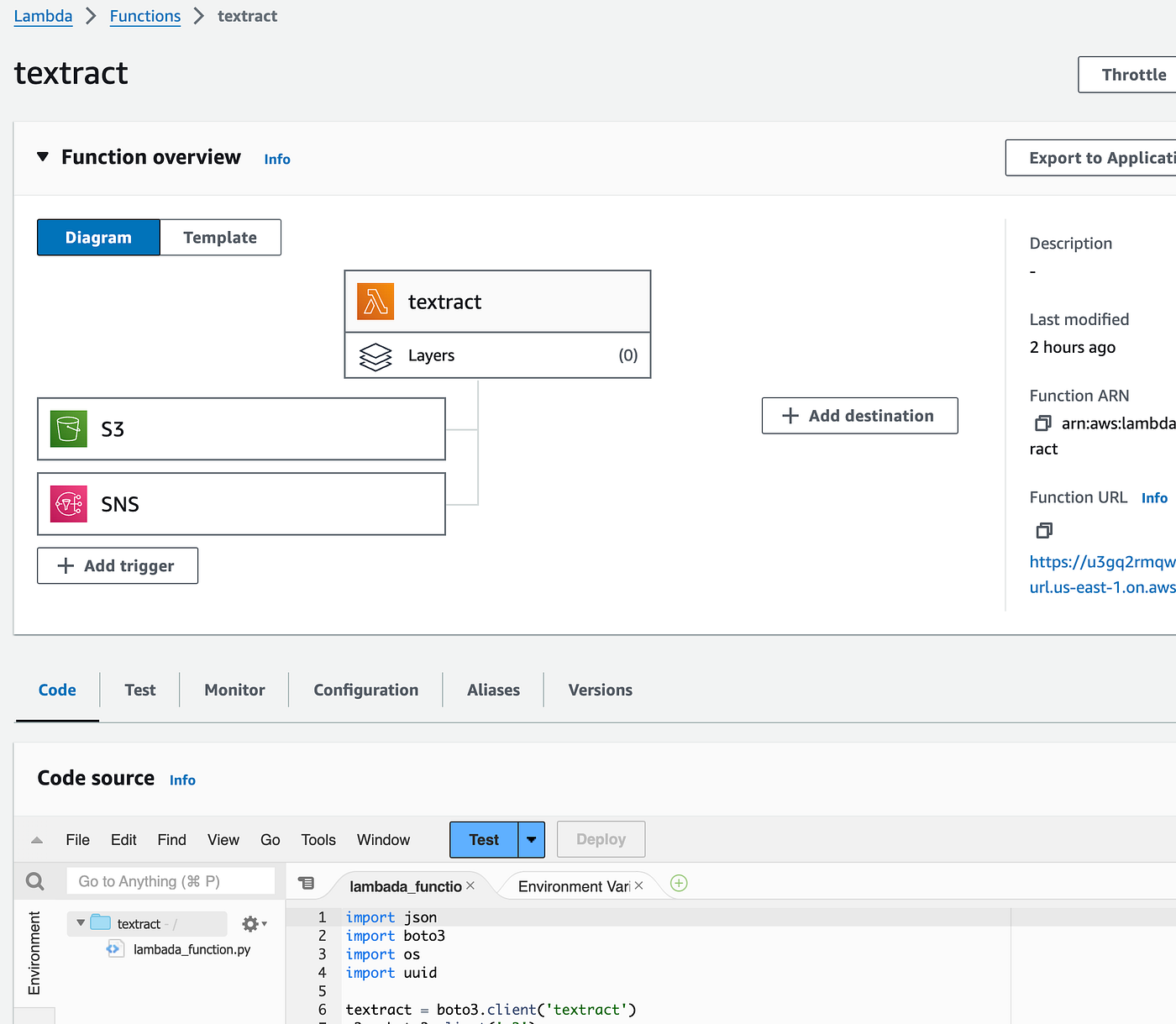
Here is what your Lambda function should look like:
You can also search using CloudSearch in the console.
That is it. There is a lot of room for improvement. Make sure you call destroy on your Terraform if this is just POC.
Mahmood
Engineer
Read More
View all posts
AI/ML
Why Enterprise AI Must Be Application-Led, Not Agent-Led
A deep dive by Todd Bernson, CTO and Chief AI Officer, on why enterprise AI systems should be architected as application-led, deterministic platforms with embedded agentic AI—not fully autonomous agents. This article explains how API-first, governed, multi-channel architectures deliver higher reliability, compliance, scalability, and business value in real-world Fortune-500 environments.

Todd Bernson
2025-12-02

AI/ML
Application-First Agentic AI
Application-first agentic AI is emerging as the only reliable path to real enterprise ROI. In this in-depth analysis, Todd Bernson, CTO & CAIO, breaks down why most generative AI initiatives stall in production—and how disciplined enterprise architecture, deterministic workflows, and narrowly scoped AI agents can finally unlock repeatable business value. Using a real sprint-intelligence system as a case study, the article shows how organizations can combine serverless engineering, structured orchestration, and constrained LLM reasoning to reduce reporting effort, increase trust, eliminate hallucinations, and deliver actionable insights across engineering, operations, compliance, and customer experience.
Todd Bernson
2025-11-28

AI/ML
Why 95% of AI Projects Fail and How to Be Among the 5% That Succeed

Lee Hylton
2025-08-22