Hyperparameter Tuning and Model Optimization
Todd Bernson, CTO, shares insights on hyperparameter tuning for XGBoost, Logistic Regression, and Deep Neural Network (DNN) models using BigQuery ML. Learn how to fine-tune parameters for optimal churn prediction performance, leveraging both manual and automated tuning techniques in GCP.

Todd Bernson
2024-11-15

Overview
Hyperparameter tuning is a critical step in machine learning, as it fine-tunes the model to achieve optimal performance. By adjusting parameters like tree depth, learning rates, and regularization, we can significantly improve a model’s accuracy, precision, and recall. BigQuery ML simplifies this process with options for manual and automated tuning, allowing you to experiment with configurations and optimize model performance efficiently.
This article focuses on the specific hyperparameters tuned for XGBoost, Logistic Regression, and DNN models in our churn prediction project, demonstrating how to achieve the best balance between complexity and performance.
Model-Specific Tuning
XGBoost Hyperparameter Tuning
XGBoost is highly customizable, and tuning its hyperparameters can greatly impact the model's ability to capture complex patterns.
Key Hyperparameters:
- max_depth: Controls the maximum depth of each decision tree. A higher depth allows capturing more intricate patterns but increases the risk of overfitting.
- learning_rate: Determines the step size for updating weights. Smaller values improve stability but require more iterations.
- num_parallel_tree: Specifies the number of trees to grow in parallel for better performance on large datasets.
SQL Query for Tuning XGBoost
CREATE OR REPLACE MODEL `<DATASET_NAME>.xgboost_tuned_model`
OPTIONS (
model_type = 'BOOSTED_TREE_CLASSIFIER',
max_depth = 8,
learning_rate = 0.1,
num_parallel_tree = 10,
data_split_method = 'RANDOM',
data_split_eval_fraction = 0.2,
input_label_cols = ['churn'],
max_iterations = 100
) AS
SELECT *
FROM `<DATASET_NAME>.<TABLE_NAME>`
churn IS NOT NULL;
This configuration:
- Uses a tree depth of 8 for a balance between complexity and overfitting.
- Sets a learning rate of 0.1 for stability.
- Grows 10 trees in parallel, optimizing for large datasets.
Logistic Regression Hyperparameter Tuning
Logistic Regression is simpler than XGBoost but benefits from tuning regularization and iteration parameters.
Key Hyperparameters:
- max_iterations: Controls how many iterations the model uses to converge.
- l1_reg (L1 Regularization): Adds penalty for non-zero coefficients, encouraging sparsity.
- l2_reg (L2 Regularization): Penalizes large coefficients, reducing overfitting.
SQL Query for Tuning Logistic Regression
CREATE OR REPLACE MODEL `<DATASET_NAME>.logistic_reg_tuned_model`
OPTIONS (
model_type = 'LOGISTIC_REG',
max_iterations = 20,
l1_reg = 0.01,
l2_reg = 0.01,
data_split_method = 'AUTO_SPLIT',
input_label_cols = ['churn']
) AS
SELECT *
FROM `<DATASET_NAME>.<TABLE_NAME>`
WHERE churn IS NOT NULL;
This configuration:
- Increases the number of iterations to 20 for better convergence.
- Sets equal values for L1 and L2 regularization to balance sparsity and stability.
DNN Hyperparameter Tuning
DNNs (Deep Neural Networks) are powerful but sensitive to hyperparameter choices, such as the number of layers, units per layer, and batch size.
Key Hyperparameters:
- hidden_units: Defines the number of neurons in each layer.
- batch_size: Determines the number of samples per training batch, affecting training speed and convergence.
- dropout: Randomly drops connections during training to reduce overfitting.
SQL Query for Tuning DNN
CREATE OR REPLACE MODEL `<DATASET_NAME>.dnn_tuned_model`
OPTIONS (
model_type = 'DNN_CLASSIFIER',
hidden_units = [128, 64, 32],
batch_size = 256,
dropout = 0.2,
data_split_method = 'RANDOM',
data_split_eval_fraction = 0.2,
input_label_cols = ['churn']
) AS
SELECT *
FROM `<DATASET_NAME>.<TABLE_NAME>`
WHERE churn IS NOT NULL;
This configuration:
- Uses three layers with progressively smaller neuron counts (128, 64, 32).
- Sets a batch size of 256 for efficient training.
- Introduces a 20% dropout rate to reduce overfitting.
Automated Tuning in BigQuery ML
BigQuery ML provides auto-tuning features, where it automatically adjusts hyperparameters during training. This is particularly useful for:
- Saving Time: Auto-tuning eliminates the need for manual experimentation with parameter values.
- Optimizing Performance: Finds the best hyperparameter settings without extensive manual effort.
To enable auto-tuning, you can use the auto_class_weights or leave hyperparameters like max_depth unset, allowing BigQuery ML to optimize them.
Code Snippets for Comparison
To evaluate the impact of tuning, run the following query to compare model metrics across configurations:
SELECT
model_name,
roc_auc,
precision,
recall,
f1_score
FROM
ML.EVALUATE(MODEL `<DATASET_NAME>.<MODEL_NAME>`,
TABLE `<DATASET_NAME>.<TABLE_NAME>`);
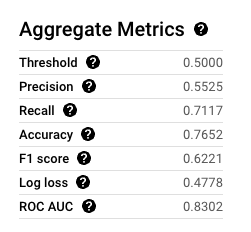
This query provides a detailed view of each model's performance metrics, allowing you to identify the best configuration.
Hyperparameter tuning is essential for extracting the best performance from machine learning models. By carefully adjusting parameters and leveraging BigQuery ML’s automated capabilities, we can create models that strike an optimal balance between accuracy, precision, and computational efficiency.
Read More
View all posts
AI/ML
Why Enterprise AI Must Be Application-Led, Not Agent-Led
A deep dive by Todd Bernson, CTO and Chief AI Officer, on why enterprise AI systems should be architected as application-led, deterministic platforms with embedded agentic AI—not fully autonomous agents. This article explains how API-first, governed, multi-channel architectures deliver higher reliability, compliance, scalability, and business value in real-world Fortune-500 environments.
Todd Bernson
2025-12-02

AI/ML
Application-First Agentic AI
Application-first agentic AI is emerging as the only reliable path to real enterprise ROI. In this in-depth analysis, Todd Bernson, CTO & CAIO, breaks down why most generative AI initiatives stall in production—and how disciplined enterprise architecture, deterministic workflows, and narrowly scoped AI agents can finally unlock repeatable business value. Using a real sprint-intelligence system as a case study, the article shows how organizations can combine serverless engineering, structured orchestration, and constrained LLM reasoning to reduce reporting effort, increase trust, eliminate hallucinations, and deliver actionable insights across engineering, operations, compliance, and customer experience.
Todd Bernson
2025-11-28

AI/ML
Why 95% of AI Projects Fail and How to Be Among the 5% That Succeed

Lee Hylton
2025-08-22